
An analog ASIC for training neural networks. 10 times cheaper or 10 times faster than digital (you pick). And a thousand times more energy efficient for both training and inference.
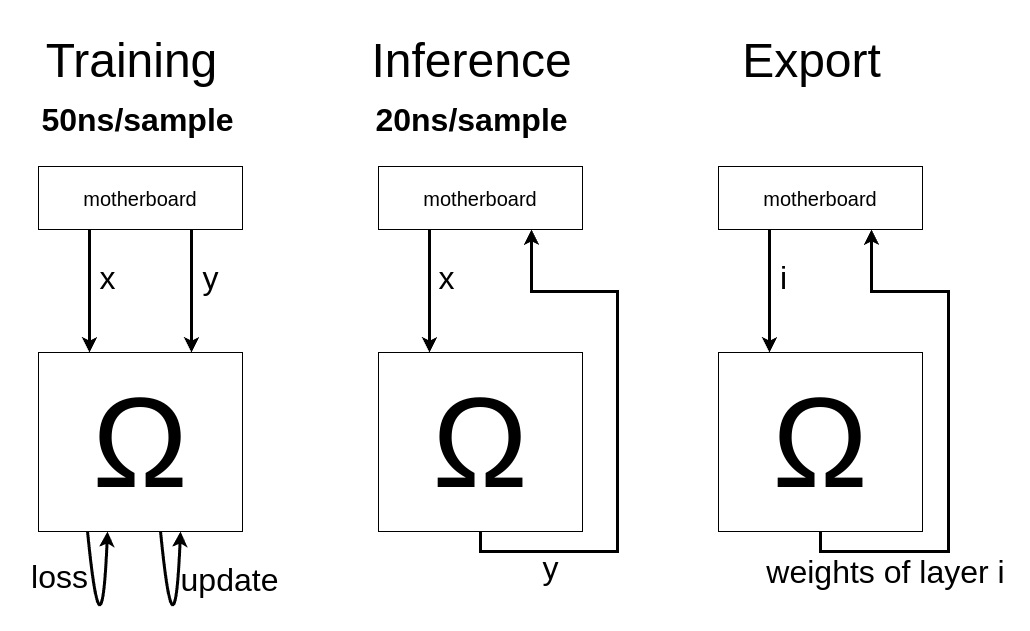
How is this possible? The chip is extremely specialized. It can only train and run MLP neural networks with ReLU activation. (Transformers will be supported in the next version.) This allows signals to propagate within the chip (or cluster) at a good fraction of the speed of light. The speed is limited by I/O therefore does not depend on the size of the neural network.
Update January 2025: The 10mm^2 prototype is finally back from the foundry and we are proceeding with testing.
Compare doing a training run with Ohm1 vs H100s:
| Ohm1 | H100 | |
|---|---|---|
| Number of cards required: | ||
| Training hardware cost: | $ | $ |
| Watts used during training: | ||
| Total watt-hours used during training: | ||
| Approx energy cost | $ | $ |
| Inference samples per watt-hour |